Modern deep learning models require activation functions that learn quickly while remaining stable and predictable when deployed in production. The Exponential Linear Unit (ELU) ticks many of those boxes.
A Brief History of Activation Functions
The earliest neural networks relied on the logistic sigmoid, whose 0–1 output range led to severe vanishing-gradient problems in deeper stacks. Tanh re-centered activations to −1…1 and trained somewhat faster, but its gradients still shrank near the extremes. ReLU (max(0, x)) alleviated this by maintaining a constant positive slope, enabling much deeper models, though its hard zero introduced “dead” neurons and a positively biased output.
ELU preserves ReLU’s fast positive behavior while replacing the hard cutoff with a smooth negative tail, encouraging activations closer to zero and reducing the risk of inactive units. This trade-off between speed and stability has made ELU a popular choice in modern research codebases.
What Is ELU (Exponential Linear Unit)?
ELU is an activation function for neural networks. Researchers introduced ELU to address two problems that engineers encountered with ReLU: dead neurons (outputs stuck at 0) and a non-zero-mean activation distribution that can slow training.
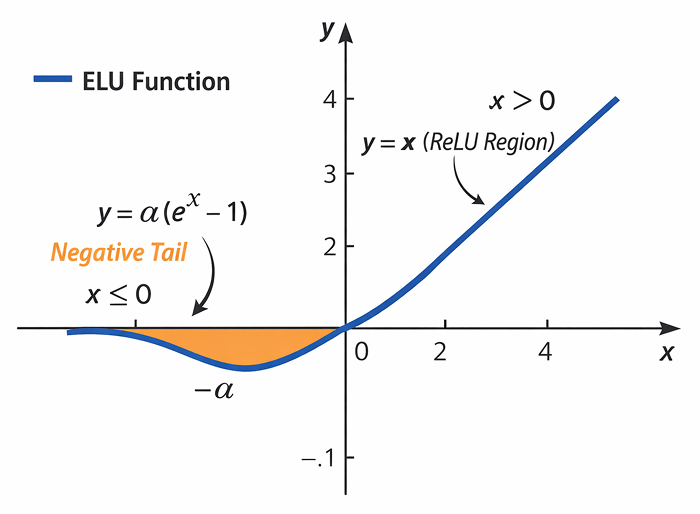
- Right of x=0 (the straight line) – 𝐸𝐿𝑈′(𝑥)=1
- Left of x=0 (the orange “negative tail”) – ELU′(x)=αex
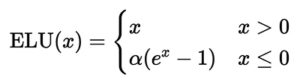
Here, α is a positive constant (often equal to 1). The curve is identical to ReLU on the positive side but smooth and negative-valued on the left. That small negative tail keeps activations centered near zero, helping gradients flow.
How the Exponential Linear Unit Activation Function Works
When a signal passes through an ELU-based layer, the exponential linear unit function treats positive and negative numbers differently:
Forward pass
- Positive inputs move straight through unchanged. If a neuron receives +3, it outputs +3, just like ReLU. So, large values keep their scale and help the model extrapolate.
- Zero or negative inputs are pushed onto a smooth exponential curve that bottoms out near −α. Instead of snapping to a hard zero (as ReLU does), ELU lets the output hover at a small negative value. This gentle bend keeps the average activation close to zero, greatly reducing the risk of dead neurons.
Back-propagation derivative
- For x > 0, the slope of the exponential linear unit derivative is exactly 1. Gradients flow freely, allowing weights connected to positive activations to learn quickly.
- For x ≤ 0, the slope is α eˣ, theoretically non-zero but can become very small for large negative inputs. So, even strongly negative neurons still receive slight weight updates. That constant trickle of gradient helps every unit keep learning, which in turn stabilizes deep networks.
Tuning with α
- The parameter α controls how far the curve dips below zero. Common values (0.5–1.5, with 1 as the default) already work well, so most practitioners set it once and focus on other hyperparameters.
- Raising α deepens the negative plateau, which can further center activations.
In practice, ELU combines ReLU’s speed on the positive side with a small negative “safety net” on the left, keeping signals balanced and gradients alive. This often results in faster convergence, fewer dead neurons, and steadier training, features that make ELU a popular default in modern deep learning libraries.
ELU vs. ReLU and Other Activation Functions
Choosing an activation is a trade-off between speed, stability, and accuracy. The comparison below highlights where ELU shines and where it doesn’t, when your model must serve high-volume, low-latency workloads that need swift fault recovery.
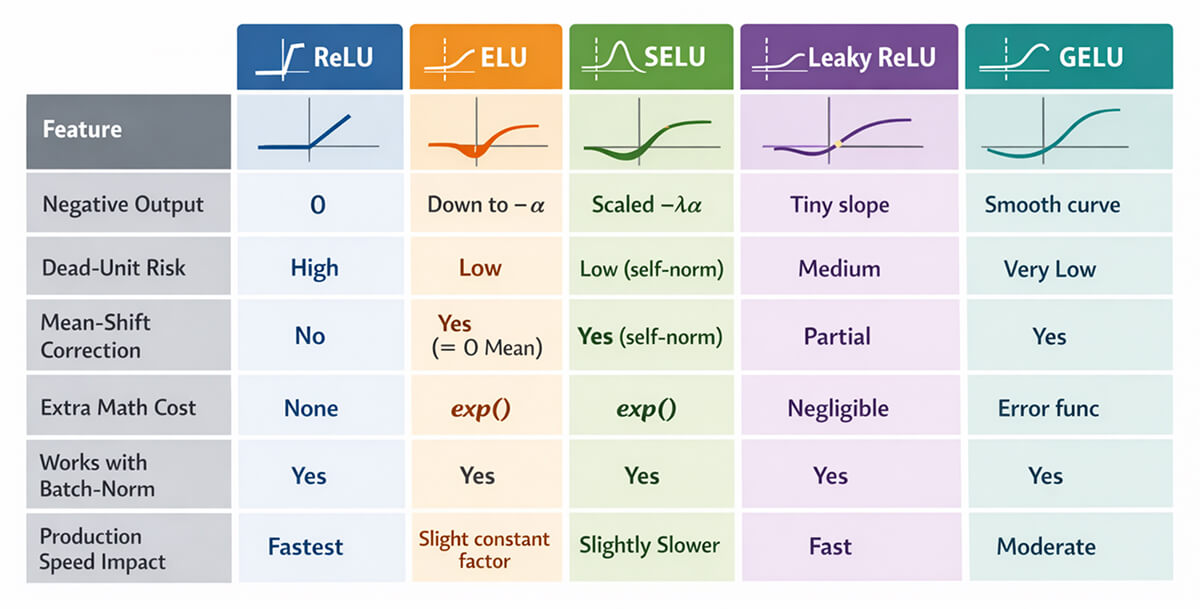
ELU vs. ReLU and Other Activation Functions
Why Teams pick ELU over ReLU
Fewer inactive neurons
ELU reduces the risk of neurons becoming permanently inactive. This is especially valuable in convolutional models deployed in production, where silent degradation can erode accuracy over time.
More stable training dynamics
By producing activations with a mean closer to zero, ELU helps gradients converge more smoothly. This improves training stability and often reduces the time needed to reach reliable performance.
Smoother behavior under extreme inputs
ELU’s continuous negative region avoids abrupt activation cutoffs, providing more graceful behavior when inputs fall outside typical ranges.
Hybrid Strategies – Mixing Speed and Stability
Teams sometimes mix activations across a network rather than committing to a single choice. One experimental pattern places ReLU in early layers, where activations are large, and computation is simple, and smoother functions, such as ELU, in deeper blocks to mitigate sparsity and improve gradient flow.
Related ideas appear in some sequence and attention architectures, where sharper nonlinearities are used in gating or control paths while smoother activations govern the main signal flow. Interestingly, neural architecture search studies often rediscover heterogeneous activation layouts, assigning fast ReLU-like units near the input and more stable nonlinearities deeper in the model, suggesting that such blends can offer a practical balance between efficiency and robustness.
Common Pitfalls & Troubleshooting
Even robust activations like ELU can fail when small setup details are overlooked. The quick checks below flag the issues that most often stall training.
Gradient decay for large negative inputs
ELU preserves a non-zero gradient for negative values, but the exponential term can still decay when inputs become strongly negative. Poor initialization or high learning rates can push activations into this regime, slowing learning. Input normalization and sensible initialization usually prevent this.
Limited gains with normalization layers
When batch or layer normalization is already in use, ELU’s negative tail may not be much better than simpler activations like ReLU. It may even add extra work for the computer.
Production issues beyond the activation function
Performance degradation often originates in data preprocessing or model-serving code rather than the activation itself. Runtime observability tools such as Hud.io help teams identify whether failures stem from the model or from surrounding application logic.
FAQs
Why is ELU preferred over ReLU in some neural networks?
ELU keeps a small, non-zero gradient for negative inputs, so neurons rarely stop learning. Its negative values also pull the mean activation toward zero, which speeds up convergence. In practice, you get more stable training and often a slight boost in final accuracy compared with ReLU.
Does the exponential linear unit help reduce vanishing gradients?
Yes. By preserving gradients for negative inputs and matching the identity for positive inputs, ELU maintains a stronger signal back through deep layers. While it doesn’t eliminate vanishing gradients, it pushes the problem deeper, allowing networks to learn richer features before any degradation occurs.
What is the difference between ELU and the scaled exponential linear unit (SELU)?
SELU applies a scaling factor λ ≈ 1.05 on top of the ELU formula, plus a fixed α ≈ 1.67. Together, they drive activations toward zero mean and unit variance without batch normalization, enabling “self-normalizing” networks. ELU alone needs external normalization, but is simpler to tune.
Is ELU suitable for deep learning models in production systems?
Yes, ELU offers near-ReLU speed yet avoids dead neurons, keeping activations centred and gradients alive over long deployments. GPUs fuse the extra exp(), so the latency impact is tiny. Native support across PyTorch, TensorFlow, and ONNX, plus straightforward quantization, makes ELU a reliable, low-friction choice for production inference at any scale.
Does using ELU affect model training speed or stability?
Training often stabilizes faster because gradients flow through all neurons. The compute time per batch rises slightly due to the exponential operation, but the wall-clock training time may still shorten since fewer epochs are needed. Overall, ELU trades a tiny per-iteration cost for quicker, more reliable convergence.