
Mar 27, 2026

A large production deployment was rolled out to the Core Backend. It bundled 63 commits across 74 files, spanning multiple unrelated changes from different owners. Approximately eight minutes after the rollout completed, alerts began firing for elevated latency and HTTP 500s in the API Gateway. No changes had been deployed to the API Gateway.
Given the size of the deployment and the absence of direct changes to the affected service, the expected remediation path would have been a full rollback followed by offline investigation.
A full rollback would have meant reverting all 63 commits, including unrelated fixes that were working as expected, re-running CI, redeploying, and revalidating the release. It would also have delayed the planned release. This was the safest default, but it carried real operational cost and risk unrelated to the actual failure.
Instead, the regression was isolated to a single commit and reverted within the hour. The release proceeded as planned.
The initial alerts pointed to increased latency and error rates in the API Gateway. At the same time, the most recent deployment targeted the Core Backend. The services are independently owned, but were deployed together as part of a shared logging infrastructure change. From the perspective of the API Gateway, no service-specific logic had changed. Without deployment-aware forensic correlation, there would have been no clear indication that the recent shared deployment was responsible for the regression, or which specific change introduced it.
With 63 commits in scope, the safest mitigation would have been to roll back the entire deployment.
The regression originated from a change to the logging layer introduced during deployment. A logger normalization function was added to recursively normalize structured objects before logging. When this function encountered Mongoose objects, it entered an infinite recursive loop.
Mongoose objects contain circular references to parent and child documents. The normalization logic did not include cycle detection or a depth limit.
As a result, the logger repeatedly traversed the same object graph, consuming CPU and blocking request processing. This led to increased latency and dropped requests. Some failures were masked by error-handling middleware that caught exceptions and returned successful responses, reducing the visibility of the underlying issue.
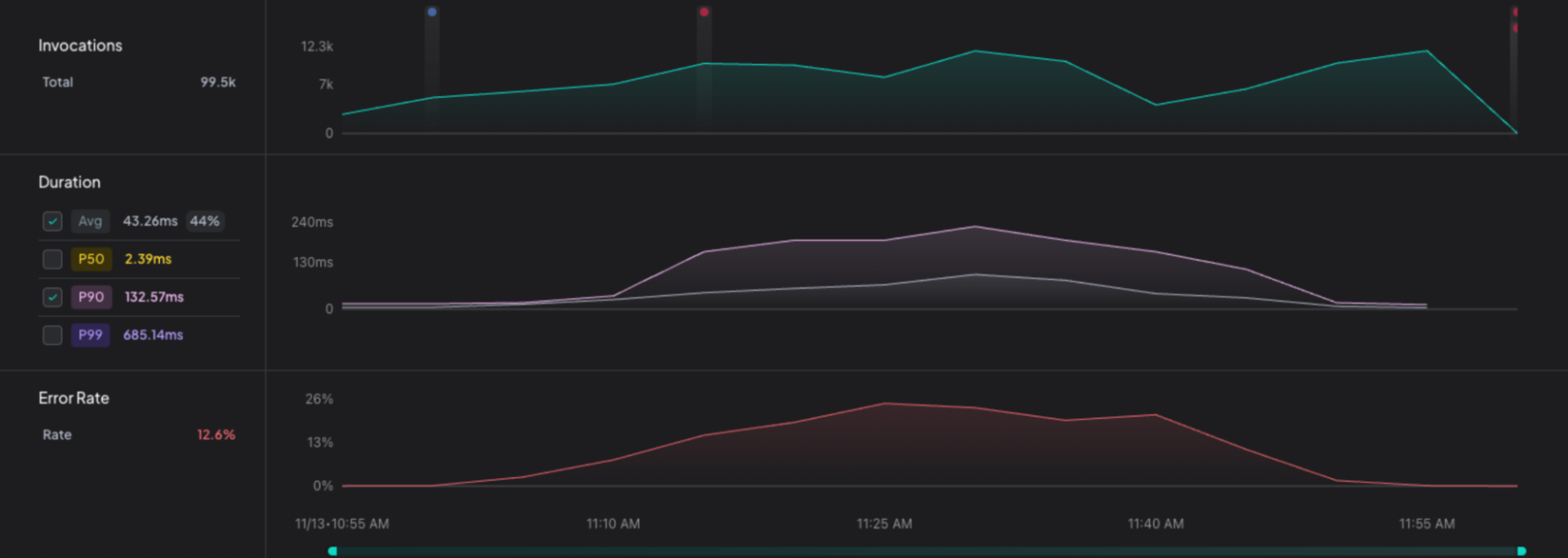
Production latency and error rates following the deployment, before mitigation.
The change passed all existing tests and showed no issues in staging or dogfood environments. No tests exercised real Mongoose documents with circular references; the failure only occurred with production-shaped data.
Runtime metrics detected a latency regression shortly after deployment. Deployment correlation showed that the behavioral change coincided with the deployment to the Core Backend, despite the symptoms appearing in the API Gateway.
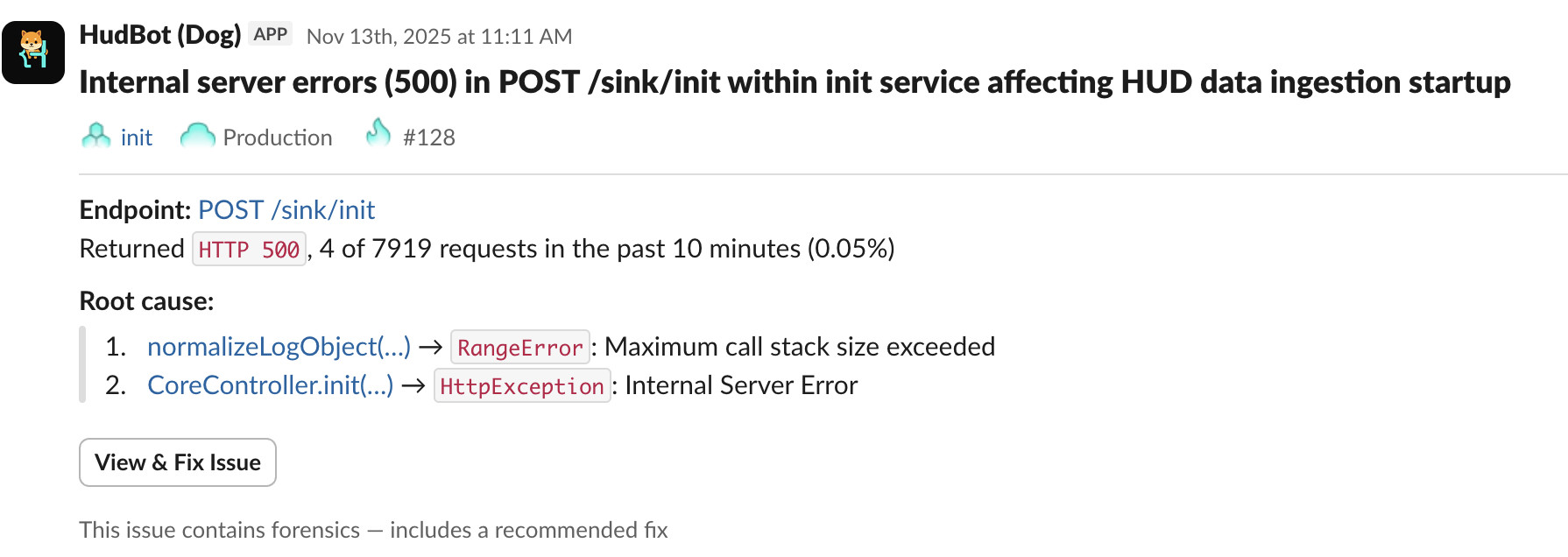
Automated alert highlighting recursive logging behavior and its impact on request handling.
Forensic data captured at runtime included function-level execution timing, execution paths, and cross-service call chains, allowing us to attribute degraded requests in the API Gateway back to an execution path introduced by the recent deployment. Specifically, we observed the same path repeatedly traversing the logger normalization function, consuming CPU in the API Gateway.
The regression was isolated to a single commit that introduced the logger normalization logic. Without cross-service deployment correlation, the investigation would have focused on the API Gateway, despite no changes having been deployed there.
A typical on-call investigation would have started in the API Gateway: reviewing recent commits (there were none), inspecting logs that showed timeouts without clear errors, adding additional logging, and attempting local reproduction. None of those steps would have surfaced the issue. The failing execution path originated in the Core Backend but manifested as resource exhaustion in the API Gateway, creating a strong signal to look in the wrong place.
This level of attribution was possible because Hud’s runtime forensics continuously capture execution context and deployment metadata in production, allowing regressions to be traced across service boundaries to an exact code change.
After isolating the offending commit, a revert was generated and merged directly to main. The rollout was accelerated to reduce the duration of the impact. No additional changes were required.
Error rates and latency returned to baseline shortly after the revert completed. The total time from detection to mitigation was under one hour.
This incident was triggered by a single commit that introduced an infinite recursive loop in the logging layer, which propagated across service boundaries and degraded request handling in a downstream service. Because the regression was isolated to a specific change, remediation consisted of a targeted revert rather than a full rollback of the deployment.
In modern distributed systems, failures often cross service boundaries, and symptoms rarely point directly to the source. Effective attribution needs to cross those boundaries as well. In this case, commit-level root cause identification enabled a surgical revert and kept the rollout on track.



